جزئیات جدیدی از کارت های گرافیکی RTX و پردازنده های امپر انویدیا منتشر شد

انویدیا اطلاعات تکمیلی جدیدی را درباره ی کارت های گرافیکی RTX 30 خود دراختیار رسانه ها گذاشت. اطلاعات جدید، جزئیاتی از عملکرد و بهره وری پردازنده های امپر (Ampere) موجود در کارت های مذکور را هم دراختیار مخاطبان قرار می دهد. اطلاعات تکمیلی، بخشی از برنامه ی بررسی عمیق محصولات انویدیا هستند که پردازنده های گرافیکی گیمینگ امپر مدل های GA 102 و GA 104 را مورد بررسی قرار می دهند. پردازنده های مذکور، به زودی و در قالب کارت های گرافیکی جدید دراختیار مصرف کننده ها قرار می گیرند.
همان طور که گفته شد، اطلاعات جدید انویدیا پیرامون محصولات جدید، علاوه بر اشاره ی مجدد به برخی از جزئیات RTX 30، بیشتر روی توانایی ها و جزئیات پردازنده ی گرافیکی امپر متمرکز می شود. انویدیا جلسه ی پرسش و پاسخی هم در ردیت برگزار کرد که اطلاعاتی جزئی در آن دراختیار مخاطبان قرار گرفت. اطلاعات جلسه ی مذکور بیشتر حول طراحی SM برای پردازنده های گرافیکی امپر تمرکز داشت. ابتدا، نگاهی به پردازنده های گرافیکی داریم که در دل کارت های RTX 30 قرار گرفته اند.
پردازنده ی گرافیکی پرچم دار GA102 (مخصوص RTX 3080 و RTX 3090)
پردازنده گرافیمی GA102 به عنوان محصول پرچم دار انویدیا در خانواده ی گیمینگ جدید شناخته می شود که در قالبی با ابعاد 628 میلی متر مربع ساخته می شود. در مجموع، 28 میلیارد ترانزیستور در این تراشه استفاده شده است. انویدیا می گوید تراشه ی GA102 شامل 6 واحد GPC (مخفف Graphics Processing Clusters) می شود و همچنین 6 واحد TPC (مخفف Texture Processing Clusters) در آن وجود دارد. تراشه ی GA102 در RTX 3090 از 41 واحد TPC یا 82 واحد SM استفاده می کند، درحالی که در RTX 3080 این اعداد به 34 واحد TPC یا 68 واحد SM می رسند. هر واحد SM در پردازنده های گرافیکی اتمپر شامل 128 هسته ی CUDA می شود که دارای ساختار بازطراحی شده هستند و در ادامه، جزئیات آن ها را شرح می دهیم. پردازنده ی GA102 در RTX 3080 دارای 10،496 هسته است، درحالی که در RTX 3080 شاهد 8،704 هسته هستیم.
پردازنده ی گرافیکی GA102 ازلحاظ چگالی، دوبرابر پردازنده ی تورینگ TU102 است و در هر میلی متر مربع، 44/56 میلیون ترانزیستور دارد. در مدل قبلی، در هر میلی متری مربع، 24/67 میلیون ترانزیستور وجود داشت. دلیل اصلی افزایش چگالی را می توان بهره برداری از روش تولید هشت نانومتری سامسونگ در پردازنده های جدید دانست.

هر واحد SM در پردازنده ی گرافیکی جدید شامل چهار هسته ی تنسور و یک هسته ی RT می شود. پردازنده ی گرافیکی GA102 از یک حافظه ی کش L2 مشترک بهره می برد. RTX 3090 دارای 6 و RTX 3080 دارای پنج مگابایت حافظه ی کش است. دیاگرام بلوکی اختصای پردازنده ی گرافیکی که ازسوی انویدیا دراختیار رسانه ها قرار گرفت، مجموع 10 کنترلر 32 بیتی حافظه را در RTX 3080 نشان می دهد که باس 320 بیتی را به هرماه دارد. کارت گرافیک RTX 3090 دارای 12 کنترلر 32 بیتی حافظه خواهد بود که رابط باس 384 بیتی را به همراه می آورد.
پردازنده ی گرافیکی GA104 (مخصوص RTX 3070)
در دل کارت گرافیک انویدیا RTX 3070، پردازنده ی گرافیکی GA104 قرار دارد. این تراشه، یکی از چندین پردازنده ی گرافیکی امپر محسوب می شود که در دسته ی گیمینگ به بازار خواهد آمد. GA104 دومین تراشه ی سریع امپر در خانواده ی جدید محسوب می شود که آن هم با روش تولید هشت نانومتری سامسونگ ساخته شده است. پردازنده ی گرافیکی مذکور، ابعاد 359/2 میلی متر مربعی داشته و 17/4 میلیارد ترانزیستور در آن قرار دارد. تعداد ترانزیستورهای GA104 حدود 93 درصد تعداد ترانزیستور GA102 می شود. فراموش نکنید که GA104 ابعادی نصف GA102 دارد و درنتیجه چگالی بسیار بالایی را در آن شاهد هستیم.




انویدیا در RTX 3070 از 46 واحد SM استفاده می کند که در مجموع، 5،888 هسته ی CUDA را دراختیار کاربر می گذارد. کارت گرافیکی RTX 3070 علاوه بر هسته های CUDA مجهز به نسل دوم هسته های رهگیری پرتو یا همان RT نیز می شود. همچنین نسل جدید هسته های تنسور و SM کاملا جدید برای استریم چندگانه ی داده در واحدها در کارت جدید استفاده می شوند. پردازنده ی گرافیکی GA104 شامل 184 هسته ی تنسور و 46 هسته ی RT می شود. البته احتمال زیادی وجود دارد که GA104 با پیکربندی 6،144 هسته ای عرضه شود که شاید در یک محصول آتی شاهد آن باشیم. پردازنده ی GA104 از چهار مگابایت حافظه ی کش L2 اشتراکی بهره می برد و در مجموع، هشت کنترلر حافظه ی 32 بیتی در آن دیده می شود. درنتیجه رابط باس این کارت گرافیک، 256 بیتی است.
مشخصات فنی کارت های گرافیک RTX 30 مجهز به پردازنده های انویدیا امپر
نام کارت گرافیک
انویدیا GeForce RTX 3070
انویدیا GeForce RTX 3080
انویدیا GeForce RTX 3090
نام پردازنده گرافیکی
Ampere GA104-300
Ampere GA102-200
Ampere GA102-300
روش تولید
هشت نانومتری سامسونگ
هشت نانومتری سامسونگ
هشت نانومتری سامسونگ
ابعاد قالب
395/2 میلی متر مربع
628/4 میلی متر مربع
628/4 میلی متر مربع
تعداد ترانزیستور
17/4 میلیارد
28 میلیارد
28 میلیارد
تعداد هسته های CUDA
5،888
8،704
10،496
TMU/ROP
نامشخص
نامشخص
نامشخص
هسته های Tensor/RT
184/46
272/68
328/82
کلاک پایه
1500 مگاهرتز
1440 مگاهرتز
1400 مگاهرتز
کلاک تقویت شده
1730 مگاهرتز
1710 مگاهرتز
1700 مگاهرتز
قدرت پردازشی FP32
20 ترافلاپس
30 ترافلاپس
36 ترافلاپس
ترافلاپس RT
40 ترافلاپس
58 ترافلاپس
69 ترافلاپس
TOPs هسته های تنسور
163
238
285
ظرفیت حافظه
8 یا 16 گیگابایت GDDR6
10 یا 20 گیگابایت GDDR6X
24 گیگابایت GDDR6X
باس حافظه
256 بیت
320 بیت
384 بیت
سرعت حافظه
14 گیگابیت برثانیه
19 گیگابیت برثانیه
19/5 گیگابیت برثانیه
پهنای باند
448 گیگابیت برثانیه
760 گیگابیت برثانیه
936 گیگابیت برثانیه
توان طراحی گرمایی
220 وات
320 وات
350 وات
قیمت
499 دلار
699 دلار
1499 دلار
تاریخ عرضه
اکتبر 2020
17 سپتامبر 2020
24 سپتامبر 2020
طراحی پردازنده ی جریان یا SM در انویدیا امپر
کارت های گرافیکی RTX 30 انویدیا مجهز به پردازنده های امپر، با طراحی کاملا جدیدی در بخش SM همراه هستند. در ادامه، جزئیات کاملی از طراحی جدید SM در معماری امپر می خوانید.

تونی تاماسی از تیم انویدیا می گوید یکی از اهداف مهم طراحی در SM در کارت های گرافیکی RTX 30 با پردازنده ی امپر، رسیدن به دوبرابر جریان عملیایتی FP32 نسبت به معماری تورینگ بوده است. واحد SM در پردازنده های امپر برای رسیدن به این هدف از طراحی مسیر داده ای جدید برای فرایندهای عملیاتی FP32 و INT32 بهره می برند. هر مسیر داده در هر جهت، شامل 16 هسته ی FP32 CUDA می شود که توانایی اجرای 16 عملیات FP32 را در هر چرخه ی کلاک دارند. مسیر داده ای دیگر شامل 16 هسته ی FP32 و 16 هسته ی INT32 می شود. درنتیجه ی این طراحی جدید، هریک از بخش های Ampere SM در هر کلاک توانایی اجرای 32 عملیات FP32 یا 16 عملیات FP32 به همراه 16 عملیات INT32 را دارد. همه ی چهار بخش SM در ترکیب با یکدیگر می توانند 128 عملیات FP32 را در یک کلاک انجام دهند که دوبرابر نرخ FP32 در واحد های SM معماری تورینگ می شود. همچنین آن ها می توانند در هر کلاک، 64 عملیات FP32 و 64 عملیات INT32 انجام دهند.
دوبرابر کردن سرعت پردازش برای FP32، قدرت و عملکرد را برای تعدادی از فرایندها و الگوریتم های مرسوم گرافیکی بهبود می بخشد. فرایندهای سایه زنی مدرن عموما ترکیبی از دستورالعمل های FP32 حسابی مانند FFMA و FADD و FMUL دارند که با دستورالعمل های ساده تر همچون جمع اعداد صحیح برای پیدا و دریافت کردن داده، مقایسه های ممیز شناور، پردازش های حداقل/حداکثر و موارد دیگر می شود. بهبود عملکرد بسته به سطح سایه زنی یا اپلیکیشن در پردازش ها متفاوت خواهد بود که به مجموعه ای از دستورالعمل ها وابسته می شود. سایه زن های حذف نویز در رهگیری پرتو مثال های خوبی هستند که احتمالا از دوبرابر شدن جریان های داده ای در FP32 سود می برند.
دوبرابر کردن جریان خروجی محاسبه در پردازنده، نیازمند دوبرابر کردن مسیرهای داده ای بود که از آن ها پشتیبانی می کردند. به همین دلیل در Ampere SM شاهد دوبرابر شدن حافظه ی اشتراکی و عملکرد کش L1 در SM هستیم. در SM امپر شاهد 128 بایت در هر کلاک هستیم که در تورینگ، 64 بایت در هر کلاک بود. انویدیا، پهنای باند L1 برای GeForce RTX 3080 را 219 گیگابایت برثانیه اعلام می کند که در مقایسه با 116 گیگابایت برثانیه در GeForce RTX 2080 Super یک بهبود قابل توجه محسوب می شود.
تاماسی در ادامه ی صحبت هایش می گوید امپر هم مانند نسل های قبلی پردازنده های انویدیا، مجهز به GPC، TPC، SM و ROP است که درکنار کنترلرهای حافظه عمل می کنند. واحد GPC را می توان یک بلوک سخت افزاری سطح بالا با سلطه ی بیشتر دانست. تمامی واحدهای پردازشی گرافیکی کلیدی در داخل GPC قرار می گیرند. هر GPC شامل یک موتور اختصاصی Raster می شود که در طراحی جدید، دو پارتیشن ROP هم در آن قرار گرفته اند. هر پارتیشن، شامل هشت واحد ROP (مخفف Raster Operators) می شود. اضافه شدن ROP را می توان قابلیت جدید پردازنده های گرافیکی مبتنی بر معماری امپر در دسته ی GA10x دانست. تاماسی در پایان صحبت هایش می گوید که به زودی جزئیات بیشتر را در سند فنی انویدیا امپر منتشر خواهند کرد.
با نگاهی دقیق تر به واحد SM در امپر، متوجه وجود 128 واحد FP32 در هر بلوک می شویم. یکی از دو مسیر داده ای FP32 می تواند به صورت هم زمان فرایندهای عملیاتی INT32 را هم انجام دهد. هزینه های تنسور شامل چهار واحد می شوند. چهار واحد بافت و یک هسته ی RT هم در هر SM دیده می شود.
































انویدیا برای هسته های نسل سومی تنسور، از همان معماری Smarsity استفاده می کند که در خانواده ی محصولات Ampere HPC هم استفاده شده بود. امپر از چهار هسته ی تنسور در هر SM بهره می برد که کمتر از هشت هسته ی موجود در هر SM در تورینگ است. ازطرفی آن ها نه تنها از طراحی نسل سوم بهره می برند، بلکه جریان های SM بزرگ تری هم دارند که موجب افزایش تعداد می شود. پردازنده های گرافیکی امپر توانایی اجرای 128 فرایند عملیاتی FP16 FMA را در هر هسته ی تنسور دارند که از کل هسته های INT16 بهره می برد و با به کار گرفتن معماری Sparsity تا 256 افزایش پیدا می کند. مجموع فرایندهای عملیاتی FP16 FMA به 512 می رسد و با به کارگیری معماری مذکور، می توان آن را به 1024 رساند. اعداد مذکور، نشان دهنده ی بهبود دوبرابری نسبت به پردازنده های گرافیکی تورینگ هستند که به لطف طراحی به روز تنسور ممکن می شود.
فرایندهای بهبود بالا برای هسته های رهگیری پرتو هم رخ می دهد که در نسل دوم، دوبرابر تداخل پرتو را نسبت به معماری تورینگ در پی دارند. بیشتر بودن تعداد واحدهای SM همچنین باعث افزایش تعداد هسته های RT هم می شود که عملکرد کلی و شتاب دهی رهگیری پرتو را به میزان قابل توجهی در امپر افزایش می دهد.
حافظه ی GDDR6X، تکامل بعدی در دنیای گرافیک
حافظه های Micron GDDR6X دستاوردهای مهمی در کارت های گرافیکی جدید دارند. این حافظه ها سریع تر هستند و درکنار دوبرابر کردن نرخ داده ی I/O، برای اولین بار از سیگنال دهی PAM4 چندسطحی در قالب های حافظه بهره می برند. حافظه های مذکور در کلاس محصولات انویدیا RTX 3090 به پهنای باند تا یک ترابایت می رسند که برای اجرای بازی های حرفه ای نسل بعد در رزولوشن 8K عالی خواهند بود.
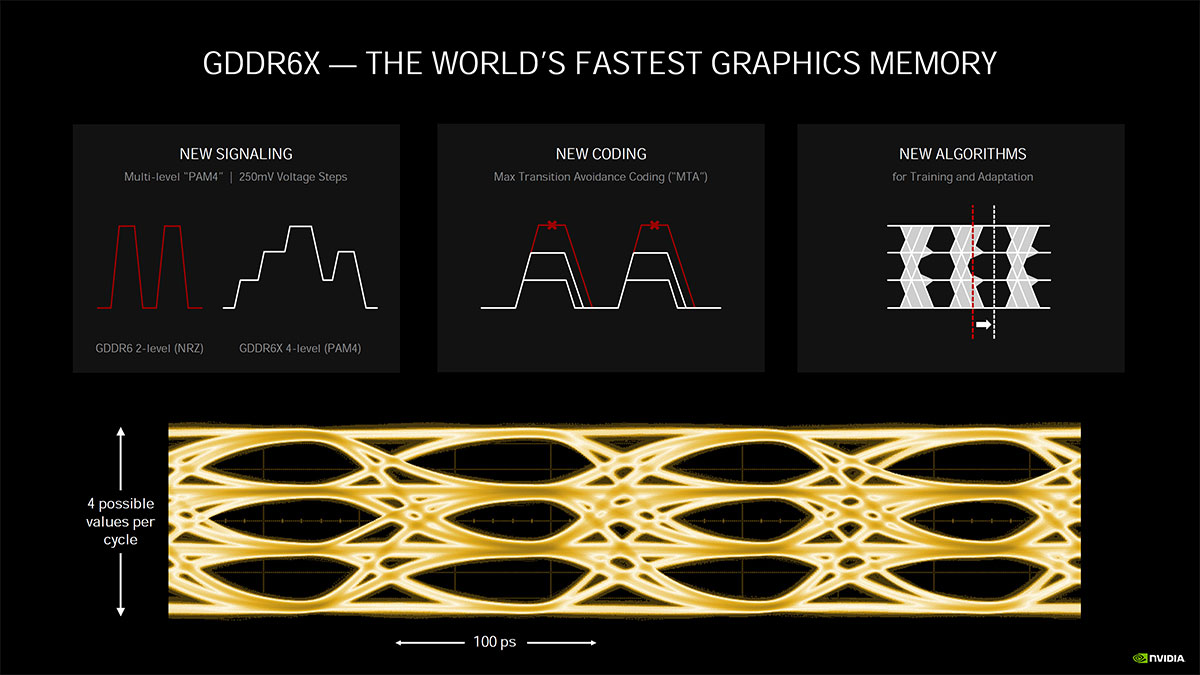
مشخصات و قابلیت های GDDR6X SGRAM جدید
نرخ داده ی SGRAM در حافظه های جدید نسبت به نسل قبلی دوبرابر می شود که در هر تراکنش، توان کمتری هم مصرف می کنند و از مرز یک ترابایت برثانیه در پهنای باند حافظه ی سیستمی فراتر می روند.
این حافظه ها، اولین دستگاه های حافظه ای اختصاصی گرافیک محسوب می شوند کع از سیگنال دهی رمزنگاری شده ی PAM4 بین پردازنده و DRAM بهره می برند. در سیستم جدید، از چهار سطح ولتاژ برای رمزنگاری و جابه جایی دو بیت از داده در هر کلاک رابط استفاده می شود.
حافظه های جدید را می توان در سرعت های بسیار بالا با پایداری مناسب طراحی کرد و به کار انداخت. امکان تولید انبوه آن ها نیز اکنون فراهم شده است.
همان طور که گفته شد، GDDR6X از سیگنال دهی چندسطحی PAM4 جدید استفاده کرده که سرعت انتقال داده را بسیار سریع تر می کند. همچنین نرخ I/O نیز بهبود پیدا می کند و ظرفیت هر قالب حافظه در آن از 64 به 84 گیگابیت برثانیه می رسد. قالب های حافظه ی Micron GDDR6x همچنین تنها DRAMهای مخصوص گرافیک هستند که می توان با وجود بهره گیری از PAM4 آن ها را به صورت انبوه تولید کرد.

نکته ی جذاب درباره ی حافظه های GDDR6X اینکه می توان سرعت آن ها را تا 21 گیگابیت برثانیه افزایش داد. البته در RTX 3090 شاهد حداکثر سرعت 19/5 گیگابیت برثانیه در آن ها هستیم. ظاهرا تولیدکننده ها می توانند قالب هایی با ظرفیت بیشتر را هم از مایکرون خریداری کنند. مایکرون همچنین تأیید می کند که برنامه هایی برای افزایش سرعت حافظه ها تا بیش از 21 گیگابیت برثانیه در سال 2021 داد، اما هنوز مشخص نیست که چه کارت هایی از این حافظه ها بهره خواهند برد.
حافظه های مایکرون GDDR6X نه تنها سرعت بیشتر، بلکه پهنای باند بیشتری را هم با 15 درصد توان مصرفی کمتر نسبت به نسل قبل ارائه می کنند.
مشخصات حافظه های GDDR6X در مقایسه با نسل های قبل
نام حافظه
GDDR5
GDDR5X
GDDR6
GDDR6X
چگالی
از 512 مگابایت تا هشت گیگابایت
هشت گیگابایت
هشت گیگابایت و 16 گیگابایت
هشت گیگابایت و 16 گیگابایت
VDD و VDDQ
1/5 یا 1/35 ولت
1/35 ولت
1/35 یا 1/25 ولت
1/35 یا 1/25 ولت
VPP
نامشخص
1/8 ولت
1/8 ولت
1/8 ولت
نرخ داده
تا هشت گیگابیت برثانیه
تا 12 گیگابیت برثانیه
تا 16 گیگابیت برثانیه
19 و 21 و بیشتر از 21 گیگابیت برثانیه
تعداد کانال
1
1
2
2
Access granularity
32 بایت
64 بایت - 2 عدد 32 بایتی در حالت pseuso 32B
دو کانال 32 بایتی
دو کانال 32 بایتی
Burst length
8
16 یا 8
16
8 در حالت PAM4 و 16 در حالت RDQS
سیگنال دهی
POD15/POD135
POD135
POD135/POD125
PAM4 POD135/POD125
پکیج
BGA-17014x12x0.8mm ball pitch
BGA-190
14x12x0.65mm ball pitch
BGA-180
14x12x0.75mm ball pitch
BGA-180
14x12x0.75mm ball pitch
عرض I/O
x32/x16
x32/x16
دو کانال x16/x8
دو کانال x16/x8
تعداد سیگنال
61
- 40 DQ, DBI, EDC
- 15 CA
- 6 CK, WCK
61
- 40 DQ, DBI, EDC
- 15 CA
- 6 CK, WCK
70 یا 74
- 40 DQ, DBI, EDC
- 24 CA
- 6 or 10 CK, WCK
70 یا 74
- 40 DQ, DBI, EDC
- 24 CA
- 6 or 10 CK, WCK
PLL, DCC
PLL
PLL
PLL,DCC
DCC
CRC
CRC-8
CRC-8
دو عدد CRC-8
دو عدد CRC-8
VREFD
در هر دو بایت، داخلی یا خارجی
داخلی در هر بایت
داخلی در هر پین
داخلی در هر پین، سه گیرنده ی زیرمجموعه در هر پین
Equalization
نامشخص
RX/TX
RX/TX
RX/TX
VREFC
خارجی
خارجی یا داخلی
خارجی یا داخلی
خارجی یا داخلی
خود نوسازی یا SRF
بله، SRF موقتی کنترل شده
بله، SRF موقتی کنترل شده و SRF هایبرنیت
بله، SRF موقتی کنترل شده و SRF هایبرنیت
VDDQ-off
بله، SRF موقتی کنترل شده و SRF هایبرنیت
VDDQ-off
اسکن
SEN
IEEE 1149.1 JTAG
IEEE 1149.1 JTAG
IEEE 1149.1 JTAG
طراحی سیستم خنک کننده در GeForce RTX 30
انویدیا یکی از بهترین طراحی های سیستم گرمایی Founders Edition را در کارت های گرافیکی RTX 30 پیاده سازی کرده است. تیم سبز می گوید عملکرد بهتر و سریع تر کارت های گرافیکی جدید، نیازمند راهکارهای خنک کننده ی بهتر بود و به همین دلیل، آن ها راهکاری مخصوص را برای نسل بعدی کارت های گرافیکی خود به کار گرفته اند. این راهکارهای جدید، پردازنده ی گرافیکی را در دمای پایین نگه می دارند و با پیاده سازی فناوری های متعدد موجود و تعدادی فناوری جدید، جلوی افزایش بیش ازحد صدای عملیاتی را هم می گیرند.
سیستم خنک کننده ی جدید فاندرز ادیشن از یک هیت سینک مخصوص با آلیاژ آلومینیم استفاده می کند که با بهره مندی از محفظه ی بخار و فن های مبتنی بر فناوری محوری دوسویه، عملکردی عالی دارد. هیت سینک خنک کننده از یک پوشش نانوکربن بهره می برد که قطعا در کنترل کردن دما موفق خواهد بود.

طراحی سیستم خنک کننده ی جدید در RTX 30 بسیار منحصربه فرد به نظر می رسد. این اولین طراحی در نوع خود محسوب می شود که آخرین بار نمونه ای مشابه با آن را در GTX 780 با هیت سینکی بزرگ دیده بودیم.
در طراحی سیستم خنک کننده ی جدید، موقعیت های خاصی برای قرارگیری فن دیده می شود که یکی در جلو و دیگری در پشت کارت قرار می گیرد. این پیکربندی کشش و مکش که با ترکیب فن دوگانه ایجاد می شود، گرما را با عملکردی ساده تر و بهینه تر از خروجی بخار کارت گرافیک استخراج می کند. البته کمی هوا به داخل کیس انتقال داده می شود که باتوجه به قدرت و کیفیت بالای سیستم های خنک کننده ی کنونی و بهره مندی از خنک کننده های مایع، مشکل زیادی ایجاد نخواهد کرد.








انویدیا تأکید می کند که طراحی جدید فاندرز ادیشن صدای کمتری نسبت به خنک کننده های سنتی دومحوره دارد و همچنین عملکردی دوبرابر بهتر از آن ها را ارائه می کند. تغییر در طراحی مصرف توان و خصوصا NVLink نقش مهمی در بهبود عملکرد سیستم خنک کننده داشته است. تغییرات جدید، جریان بهتر هوا را در از میان بزرگ ترین مجموعه ی فین طراحی شده تا به امروز، آسان تر می کند. منافذ براکتی بزرگ تر در ساختار خنک کننده در ترکیب با فین های خاص، جریان بزرگ تری از هوا را ممکن می کنند. از هر جهت که نگاه کنید، طراحی فاندرز ادیشن با تمرکز بر افزایش جریان هوا انجام شده است. به حداقل رساندن دما و رسیدن به بالاترین سطح عملکرد با کمترین صدا، همگی در طراحی جدید لحاظ شده اند.
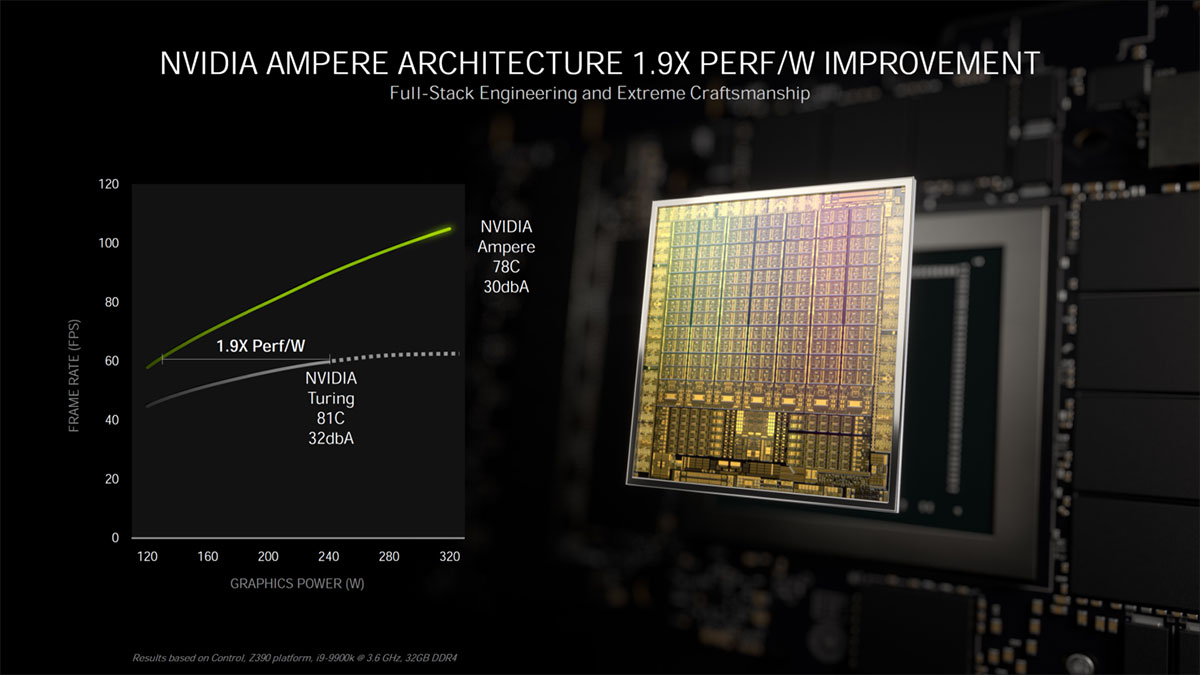
کارت گرافیک RTX 3080 در مبحث صدای خنک کننده و عملکرد، در حداکثر دمای 78 درجه ی سانتی گراد عمل می کند. کارت گرافیک مذکور برای رسیدن به حداکثر باید به توان 320 وات برسد که در آن حالت، خروجی صدای 30 دسی بل خواهد داشت. در مقام مقایسه، کارت گرافیک تورینگ فاندر ادیشن حداکثر دمای 81 درجه ی سانتی گراد داشت و حداکثر صدای آن نیز با توان 240 وات، 32 دسی بل گزارش می شد (کارت گرافیک RTX 2080 Super).
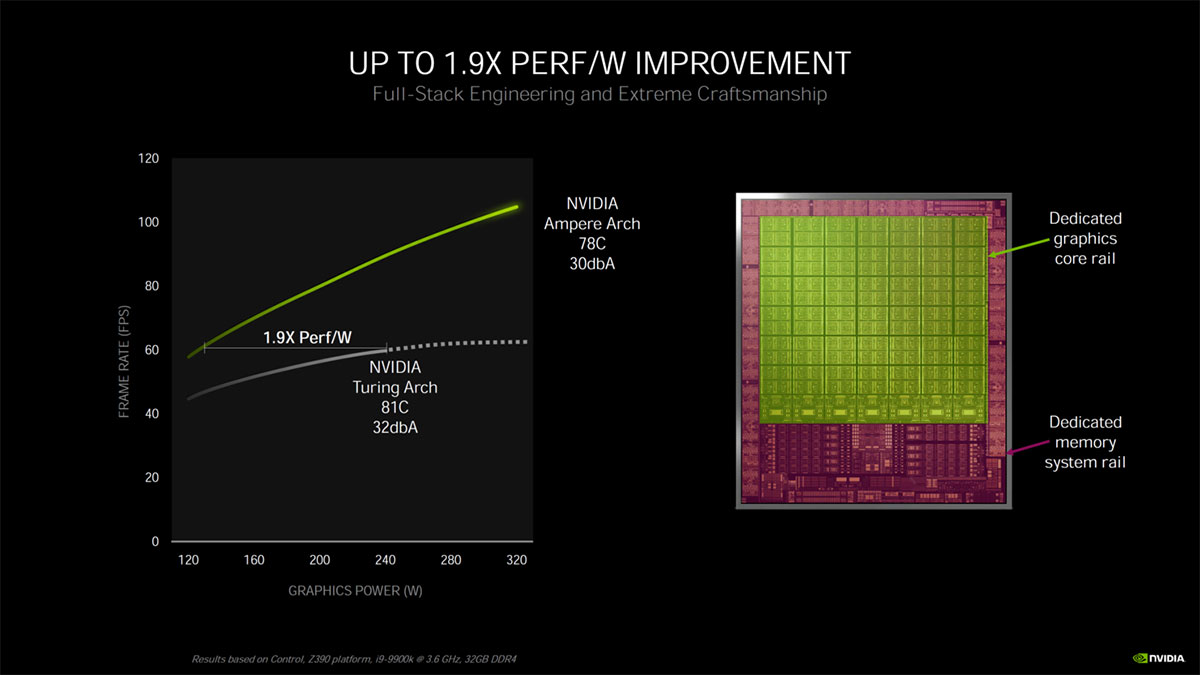
در آزمایش های اختصاصی تیم سبز، RTX 3080 فرکانس میانگین 1920 مگاهرتز را با توان مصرفی 310 وات ثبت می کند که حداکثر دمای آن را به 76 درجه می رساند. انویدیا در همین مقایسه، فاکتور 1/9 برابر را مطرح کرده و ادعا می کند که RTX 3080 با صدا و دمای کمتر امکان ارائه ی خروجی 100 فریم برثانیه را دارد که در مقایسه با 60 فریم برثانیه ی نسل قبلی، یک پیشرفت محسوب می شود.
طراحی برد PCB و توان RTX 3080 و RTX 3090
یکی از تغییرهای عمده ای که در کارت گرافیک RTX 3090 Founders Edition دیده می شود، در طراحی PCB نهفته است. کارت های گرافیکی RTX 3080 و RTX 3090 با پکیجینگ منحصربه فرد و کامپکت PCB طراحی و ساخته می شوند که قبلا در فضای مصرف کننده در هیچ جا دیده نشده بود. ازطرفی کامپکت بودن طراحی بدین معنی نیست که کارت ها توان مصرفی زیای ندارند. انویدیا در همین کارت های کامپکت مجموعه ای با توان طراحی بسیار بالا قرار داده است.

برد PCB در کارت های جدید انویدیا شامل 20 بخش مصرف کننده ی توان می شود که طراحی خاص و حرفه ای آن را در مقایسه با کارت های RTX 20 پرچم دار نشان می دهد. پردازنده ی گرافیکی توان مورد نیاز خود را از 18 فاز دریافت می کند و توان حافظه نیز از دو فاز دیگر تأمین می شود. انویدیا می گوید این نوع از PCB یک محصول عالی برای اورکلاک محسوب می شود که کاربران با استفاده از آن، به توان های بسیار بالاتری خواهند رسید. البته PCB در نسخه ی فاندرز ادیشن با نسخه ی عادی تفاوت دارد و در نسخه های مرسوم، از همان طراحی چهارگوش استفاده می شود.

کارت های گرافیکی RTX 30 مدل فاندرز ادیشن علاوه بر طراحی جدید، از کانکتورهای برق 12 پینی Micro-Fit 3.0 بهره می برند. این کانکتورها نیازی به ارتقا منبع تغذیه ایجاد نمی کنند چون با رابط های 2x8pin به 1x12pin عرضه می شوند و می توان بدون مشکل تأمین توان، از آن ها بهره برد.
جانمایی کانکتورهای 12 پینی روی PCB در کارت های جدید انویدیا یک نوآوری دیگر را از تیم سبز نشان می دهد. پین ها به صورت عمودی جانمایی شده اند و باتوجه به طراحی PCB، می توان دلیل استفاده از طراحی 12 پینی را به جای طراحی استاندارد هشت پینی استاندارد متوجه شد. در PCB فضای محدودی برای انجام فرایندهای این چنینی وجود دارد و باید از ورودی توان کوچک تر استفاده می شد.
عملکرد، زمان عرضه و قیمت RTX 30
انویدیا در اطلاعات تکمیلی خود جزئیاتی از اعداد و ارقام توان در کارت های گرافیکی جدید منتشر کرد. در نمودارهای زیر، توان و عملکرد کارت های RTX 3070 و RTX 3080 و RTX 3090 v را مشاهده می کنید.
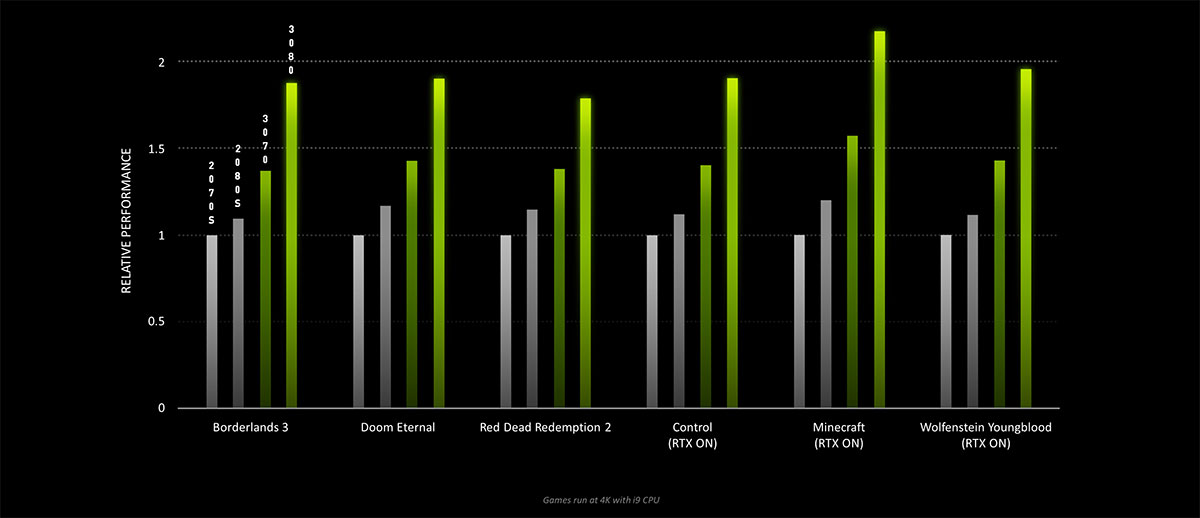
انویدیا هنوز هیچ آمار و ارقام دقیقی درباره ی کارت های جدید سری RTX 30 منتشر نکرده است، اما باتوجه به همین رونمایی کلی هم می توان پیش بینی کرد که RTX 3070 عملکردی بالاتر از RTX 2080 Ti دارد و RTX 3080 بسیار بهتر از RTX 2080 Ti خواهد بود. کارت گرافیک پرچم دار RTX 3090 هم که سرعتی تقریبا 50 درصد بهتر از RTX 2080 Ti دارد و بهبودی عالی را در مجموعه ی خانواده ی جدید نشان می دهد.




درواقع انویدیا پیش نمایشی کلی را از عملکرد و قدرت کارت های جدید به نمایش گذاشت. آن ها پیش نمایشی از Doom Eternal را با RTX 3080 نمایش دادند که بسیار بهتر از RTX 2080 Ti ظاهر شد و همچنین توانایی عالی کارت در اجرای بازی های 4K هم به نمایش گذاشته شد. در اکثر بازی های AAA، کارت های جدید انویدیا توانایی رسیدن به حداکثر نرخ فریم 60 فریم برثانیه را دارند.
















درنهایت نوبت به اطلاعات قیمت و زمان عرضه ی کارت های جدید انویدیا می رسد. تیم سبز می گوید RTX 3080 اول از همه و در تاریخ 17 سپتامبر به بازار عرضه می شود. پس از آن نوبت RTX 3090 خواهد بود که 24 سپتامبر به بازار می آید و درنهایت RTX 3070 در ماه اکتبر به مصرف کننده ها عرضه می شود. ازلحاظ قیمت نیز کارت ها به ترتیب 1،499 و 699 و 499 دلار قیمت خواهند داشت. به زودی نسخه های سفارشی و پرمیوم نیز با قیمت های متنوع معرفی می شوند.
دسته بندی : سبک زندگی
مقالات مرتبط
- مانيتور LG مدل E90 به باريكي 7.3 ميليمتر
- عرضه بازی Vampire: The Masquerade - Bloodlines 2 به سال 2021 موکول شد
- 13 خطای امنیتی متداول که کامپیوتر را آسیب پذیر می کند
- Modern Warfare 3 رکورد فروش در 5 روز اول باکس آفیس، کتاب و بازی را شکست
- -
- بهترین روشهای شاد زیستن
- تصاویر جدید از پشت صحنه Jurassic World: Dominion به دایناسورهای کوچک اشاره دارد
- رونمایی از دو لنز جدید تله فتو کانن
- همکاری هری پاتر با گوگل برای ساخت وب سایت Pottermore
- هیوندای سوناتا N لاین 2021 معرفی شد
- پفک یا چیتوز ؟
- صفحه تب جدید مرورگر کروم را با گزارش آب و هوا و ساعت جایگزین کنید
- اپل عنوان با ارزش ترین برند دنیا را از آن خود کرد، گوگل جا ماند
- بررسی بازی Tell Me Why از دید سایت های معتبر دنیا
- کارل مارکس؛ معمار تفکر رهاییبخش
- ویدئو: آموزش فیلمبرداری با دوربینهای کانن – بخش دو
- با ارزان ترین دوربین DSLR کانن آشنا شوید
- مقایسه لنز های 70-200 میلیمتر در کانن و سیگما و تامرون
- پایه جواهر چیست و چطور می توان پایه جواهر داشت
- مارتین اسکورسیزی برای شرکت فیلمسازی خود با اپل قرارداد امضا کرد
منبع : تیاندا